
Partager cette page :






Visualisation et fouille de données
le 16 septembre 2008
10h15 - 12h15
ENS Rennes Salle du conseil
Plan d'accès
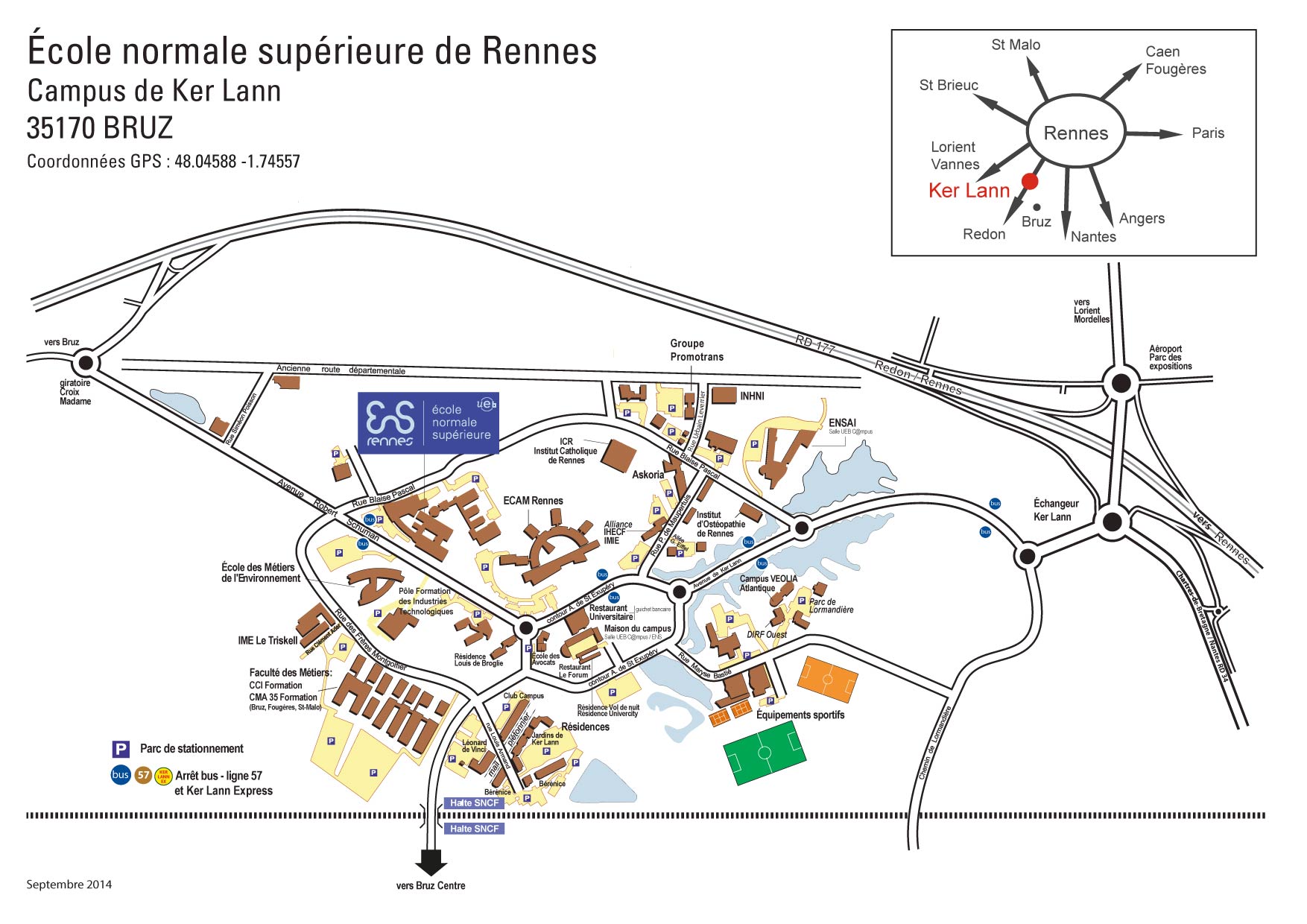{kind=link}
Intervention de François Poulet, maître de conférences à l'Université de Rennes 1
et chercheur dans l'équipe TexMex de l'IRISA (séminaire du département Informatique et télécommunications).
Il s'agit d'une recherche sur la visualisation et l'extraction de connaissances dans les données.
L'extraction de connaissances dans les données peut être définie comme le processus non trivial de découverte de connaissances nouvelles, potentiellement utiles et compréhensibles dans les données. La fouille de données concerne plus précisément le coeur de ce processus : la découverte de connaissances nouvelles. Ce domaine relativement récent d'extraction de connaissances dans les données regroupe des travaux de plusieurs domaines de recherche : les bases de données, l'apprentissage symbolique automatique, les statistiques, l'analyse de données et la visualisation. Dans les approches usuelles, la visualisation n'intervient en général que lors de deux étapes particulières du processus de fouille de données :
Entre ces deux étapes il y a en général exécution d'un algorithme automatique de fouille de données. Le but de nos travaux de recherche est d'augmenter le rôle de la visualisation dans ce processus. Ceci peut être mené à bien de plusieurs façons :
Par ailleurs une limite connue des algorithmes de visualisation est la difficulté à traiter des ensembles de données de grandes tailles (en nombre d'individus ou lignes de la base de données ou en nombre d'attributs ou colonnes de la base de données). L'approche coopérative utilisant simultanément des algorithmes automatiques et graphiques est un excellent moyen de pouvoir dépasser les limites des outils de visualisation, on parle de "passage à l'échelle".
Le séminaire présentera les travaux menés dans ces directions.
L'extraction de connaissances dans les données peut être définie comme le processus non trivial de découverte de connaissances nouvelles, potentiellement utiles et compréhensibles dans les données. La fouille de données concerne plus précisément le coeur de ce processus : la découverte de connaissances nouvelles. Ce domaine relativement récent d'extraction de connaissances dans les données regroupe des travaux de plusieurs domaines de recherche : les bases de données, l'apprentissage symbolique automatique, les statistiques, l'analyse de données et la visualisation. Dans les approches usuelles, la visualisation n'intervient en général que lors de deux étapes particulières du processus de fouille de données :
- dans l'une des toutes premières étapes pour "voir" les données ou leur distribution,
- dans l'une des toutes dernières étapes du processus pour prendre connaissance des résultats.
Entre ces deux étapes il y a en général exécution d'un algorithme automatique de fouille de données. Le but de nos travaux de recherche est d'augmenter le rôle de la visualisation dans ce processus. Ceci peut être mené à bien de plusieurs façons :
- en faisant collaborer des méthodes visuelles avec les méthodes automatiques soit en pré-traitement soit en post-traitement,
- en remplaçant l'algorithme automatique de fouille de données par un algorithme graphique interactif, on parle alors de fouille visuelle de données ou "Visual Data Mining".
Par ailleurs une limite connue des algorithmes de visualisation est la difficulté à traiter des ensembles de données de grandes tailles (en nombre d'individus ou lignes de la base de données ou en nombre d'attributs ou colonnes de la base de données). L'approche coopérative utilisant simultanément des algorithmes automatiques et graphiques est un excellent moyen de pouvoir dépasser les limites des outils de visualisation, on parle de "passage à l'échelle".
Le séminaire présentera les travaux menés dans ces directions.
- Thématique(s)
- Formation, Recherche - Valorisation
- Contact
- Claude Jard
Mise à jour le 9 septembre 2019
Contact
Archives
- Séminaires 2021-2022
- Séminaires 2020-2021
- Séminaires 2019-2020
- Séminaires 2018-2019
- Séminaires 2017-2018
- Séminaires 2016-2017
- Séminaires 2015-2016
- Séminaires 2014-2015
- Séminaires 2013-2014
- Séminaires 2012-2013
- Séminaires 2011-2012
- Séminaires 2010-2011
- Séminaires 2009-2010
- Séminaires 2008-2009
- Séminaires 2007-2008
- Séminaires 2006-2007
- Séminaires 2005-2006
- Séminaires 2004-2005
- Séminaires 2003-2004
- Séminaires 2002-2003